 (Photo: Unsplash)
(Photo: Unsplash)
“When the opportunity came around, she knew she had to get her act ________ and hit the ground _______ to secure the deal. This was her chance to strike while ___ ____ __ ___.”
Did your mind fill in the blanks as you read that? If you’re familiar with the English language, it probably did.
Up to the early 2000s, computers weren’t able to do what you just did.
But today, Large Language Models (LLMs) can well achieve that. In fact, these advanced artificial intelligence (AI) models are revolutionising the way systems understand and generate human language by identifying patterns, interpreting context, predicting the next word in a sentence and producing coherent responses.
With their natural language processing (NLP) capabilities – which focuses on translating between human and computer languages – they power many of the digital applications we use in our daily lives, from customer service chatbots and smart home controls to search engines and content generators.
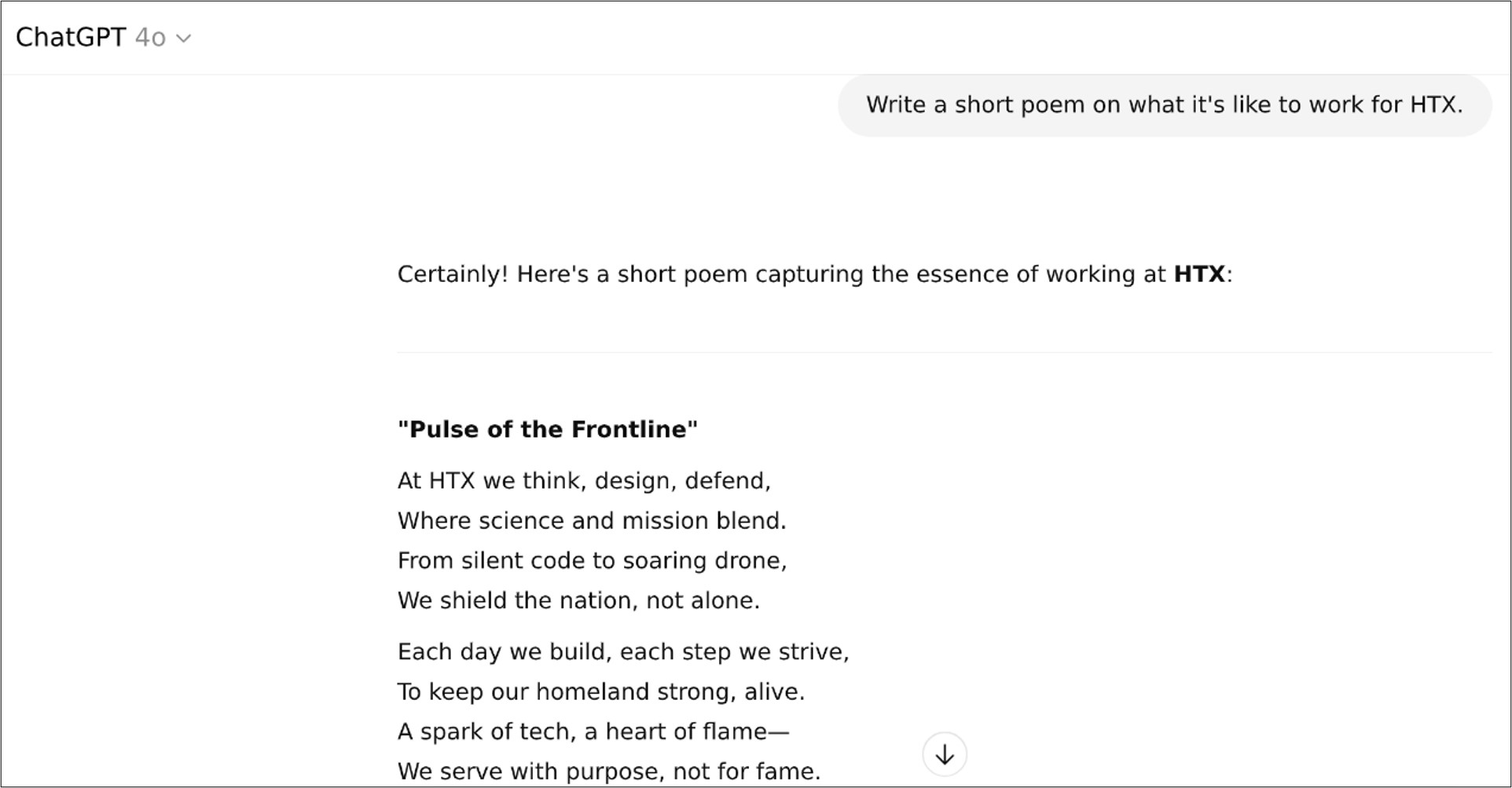 LLMs can even write creative poems! (Screenshot: OpenAI)
LLMs can even write creative poems! (Screenshot: OpenAI)
Machine learning
Like humans, LLMs aren’t born smart – they have to be trained on massive corpora of text, from books and articles to websites and social media posts, in order to learn grammar, semantics and context through a process called “pre-training”.
How massive is massive? Well, if you attempted to read all the data used to train OpenAI’s 2020 Generative Pre-trained Transformer 3 (GPT-3) model, it would take you a whopping 2,600 years.
And that’s how the “large” label is derived. But with such overwhelming datasets, how does an LLM learn it all?
You see, at the core of LLMs are neural networks– a series of algorithms, or neurons, that mimic the way human brains process information. An untrained model may generate gibberish at first, but when fed more examples – billions of them – it can start to make sense of the text inputs and fine-tune its predictions for what word should come next.
 Recurrent neural networks process sequential data such as text and speech, while convolutional neural networks process data with grid-like topology, such as images. (Photo: Unsplash)
Recurrent neural networks process sequential data such as text and speech, while convolutional neural networks process data with grid-like topology, such as images. (Photo: Unsplash)
A pre-trained LLM doesn’t just choose the most obvious word - it evaluates probabilities for several possible words and chooses the most likely, leveraging an algorithm known as “backpropagation”.
The learning doesn’t just stop there either. Just as humans engage in lifelong learning, LLMs undergo reinforcement learning with human feedback, which is provided when trainers flag and correct “bad behaviour”. This helps further refine the models’parameters, increasing the likelihood of them giving more useful and accurate outputs.
Rising intelligence
So, how did such sophisticated technology come about in the last two decades?
We’d have to go way back to the foundations of conversational AI, symbolic AI and rule-based systems in the 1950s to 1980s, which were highly inspired by the groundwork of mathematics and linguistics pioneers like Alan Turing and Noam Chomsky.
Early chatbots, such as ELIZA, which was released in 1966, used basic pattern matching to rephrase text inputs into responses. If a user said, in a psychotherapy context, “I am feeling sad,” ELIZA would rephrase and respond with, “Why are you feeling sad?”.
 A mock-up of a conversation with ELIZA, the world’s first chatbot. (Image: OpenAI)
A mock-up of a conversation with ELIZA, the world’s first chatbot. (Image: OpenAI)
As datasets and computational power grew through the 90s, the world saw a shift to statistical methods in NLP, such as probabilistic and n-gram models. These were able to better predict the next word in a sequence.
In 1997, Long Short-Term Memory (LSTM) networks revolutionised sequence processing, enabling models to remember information across long sequences.
But the emergence of modern LLMs, or pre-trained models, only took place in the 2010s, when Google’s 2013 Word2Vec and Stanford’s 2014 GloVe were able to capture semantic relationships in words. Models could now link words with similar meanings, such as “ice” and “cold”.
Google’s 2015 Seq2Seq model also allowed for more robust machine translation and text summarisation.
The most significant breakthrough came in 2017, when Google introduced transformers – and we don’t mean Optimus Prime – which could imbibe words all at once instead of having to process each word.
 Examples of conversational AI tools that use the transformer architecture. (Photo: Unsplash)
Examples of conversational AI tools that use the transformer architecture. (Photo: Unsplash)
Language is encoded as numbers in a process called “tokenisation”, and with their “self-attention” mechanism, transformers use the numbers to speak to each other and capture the context of other numbers around, no matter their distance in the sequence.
Their “feed-forward” neural network also gives the LLM additional capacity to store more patterns as it learns. This has enabled faster parallel processing, setting the stage for today’s powerful conversational AI models such as Google’s Gemini and OpenAI’s ChatGPT.
Force multiplying the Home TeamLLMs have come a long way and there are plans to make them even better. After all, their versatility has boosted productivity in many processes and brought convenience to countless people.
How? Well, LLMs can automate mundane tasks like text summarisation, translate lengthy write-ups, debug code and identify threats in cybersecurity, and even generate scripts for automatic responses.
 LLMs can augment threat detection and improve incidence response in cybersecurity systems. (Photo: Freepik)
LLMs can augment threat detection and improve incidence response in cybersecurity systems. (Photo: Freepik)
In the context of the Home Team, these capabilities can support efforts to save lives, solve crimes, and safeguard data.
LLMs can also boost real-time information sharing and communication, improve situational awareness and predictive capabilities, streamline training, and enhance data analysis for public safety operations such as emergency response and crime prevention.
Besides integrating them into technological solutions for the Home Team, such as in Embodied AI robots, HTX has also created its own series of LLMs called Phoenix.
One to call our ownYou’re probably wondering why the Home Team would need its own LLMs.
The answer? Because LLMs that are available in the market would likely not understand unique jargon and processes within the Home Team context.
“Training LLMs with our own materials and examples means more specific learning, which translates to more relevant outputs, and greater customisation and explainability,” explained Wang Jia Le, an engineer from HTX’s Q Team Centre of Expertise (CoE).
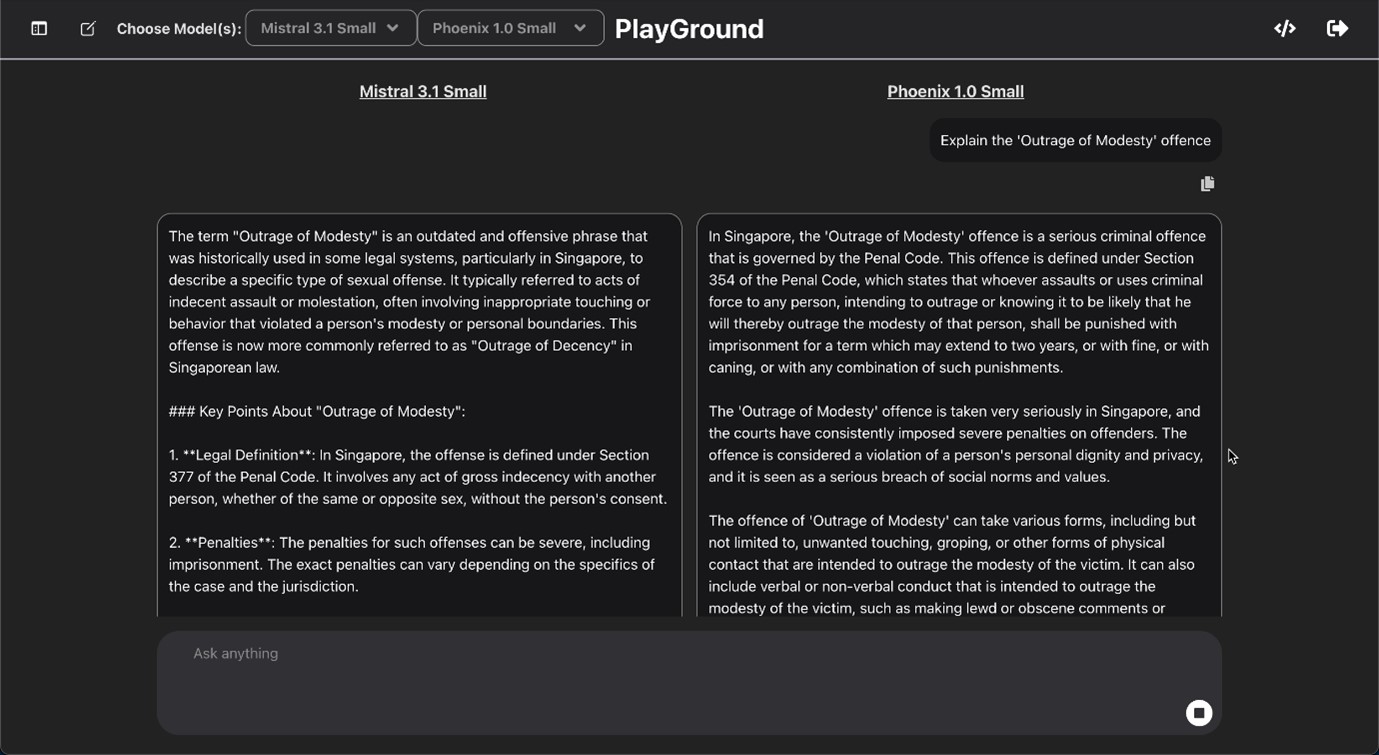 See how the output of Phoenix (right) compares with that of other models when queried about home affairs. (Screenshot: HTX)
See how the output of Phoenix (right) compares with that of other models when queried about home affairs. (Screenshot: HTX)
For example, a firefighter who needs to do research on a topic specific to Singapore or Singapore Civil Defence Force will very unlikely find what he or she needs from a chatbot powered by a commercially available LLM.
This is why Phoenix has been pre-trained on a massive amount of data pertaining to the Home Team and Singapore. In fact, it can even communicate in eight commonly spoken languages in Singapore, including Bahasa Melayu and Tamil.
“LLMs continue to show potential in a diverse range of tasks, from summarising and generating case reports to entity extraction and multimodal analytics. We hope that AI can improve citizens’ interactions with the Home Team and improve employee experience and productivity,” he said.
@htxsg Our AI engineer shows how thinking like an AI talent doesn’t stop after hours. So what do you think... should we wear more autumn colours? 🍁 #HTXsg #HTxAI #EverydayAI ♬ original sound - HTX Singapore
Jia Le, however, pointed out that LLMs still quite aren’t the perfect encyclopaedia, noting that models can sometimes hallucinate and produce strange or erroneous results, depending on how they have been trained.
“At times, they can even be biased or give answers not aligned to the Singapore government’s policy stances,” he quipped.
“This is why our team puts in a lot of effort to further finetune models in the post-training stage. This ensures that their answers are safe and aligned to our values.”
Jia Le also cautioned against over-reliance on LLMs and said that human expertise and intuition must never take a back seat.
“LLMs generate responses by predicting likely word patterns based on training data—they do not fully understand content or verify truth, even though researchers are trying very hard to improve this. Besides, we need to ensure we have the capability for critical thinking, because that’s what sets us apart from the machines,” he said.
